
The Windows of the AI Age Will Probably Not Be a Window

Why voice is the natural endpoint of human-computer interaction, why the model layer may be disintermediated by the interaction layer, and why a neglected Gartner category may be hiding the next operating system company.
“People often overestimate what will happen in the next two years and underestimate what will happen in ten.” Bill Gates is the source most often attached to that line from The Road Ahead, and whether you prefer that formulation or Roy Amara’s law, the point is the same: technological change usually looks overhyped right before it looks obvious. (Wist.info)
Grad’s desk, 2035
 It is 7:12am on some not-very-distant morning in 2035. I sit down at my desk in New York with coffee in hand. There are no tabs open. No dashboard blinks at me with the haunted energy of enterprise software trying to look useful. No one expects me to spelunk through menus, remember where someone hid the settings, or click through sixteen nested screens to find the one thing I actually need.
It is 7:12am on some not-very-distant morning in 2035. I sit down at my desk in New York with coffee in hand. There are no tabs open. No dashboard blinks at me with the haunted energy of enterprise software trying to look useful. No one expects me to spelunk through menus, remember where someone hid the settings, or click through sixteen nested screens to find the one thing I actually need.
I just start talking.
“Good morning. What matters today?”
And the machine talks back.
“Three things. First, the board deck needs a sharper narrative on margin expansion because finance still does not buy the argument. Second, our market perception shifted overnight after yesterday’s analyst note; I have the narrative diff ready. Third, your one o’clock meeting is underprepared. I pulled the last three earnings calls, leadership changes, buyer sentiment, and open procurement issues. Which one do you want first?”
That is not a product demo. It is not a chatbot. It is not voice search. It is not even, really, software in the way we have come to think about software. It is something larger: an operating environment in which natural language becomes the primary way I invoke intelligence, orchestrate work, and move through my day.
That future still sounds futuristic enough that many people dismiss it as a thought experiment. I do not. I think we are backing into it right now, awkwardly and unevenly, the way we usually do when a real interface shift is underway. The tell is not that the technology suddenly becomes magical. The tell is that the old interface starts to look tired. And once that happens, history tends to move faster than incumbents expect.
The tell is not that the technology becomes magical. The tell is that the old interface starts to look tired.
Better tools do not make us less human
A great deal of the handwringing over AI strikes me as nonsense.
 The printing press did not make human thought less human. Sure, a few scribes lost their scribing jobs—or whatever the proper medieval guild language for that was—but think of what got unleashed. Before printing, the number of manuscript books in Europe could be counted in the thousands. By 1500, after only fifty years of printing, there were more than nine million books. That is what better tools do. They widen participation, lower friction, and set off second-order innovation no one can count in advance. Britannica’s history of early printing makes the scale of that shift vivid.
The printing press did not make human thought less human. Sure, a few scribes lost their scribing jobs—or whatever the proper medieval guild language for that was—but think of what got unleashed. Before printing, the number of manuscript books in Europe could be counted in the thousands. By 1500, after only fifty years of printing, there were more than nine million books. That is what better tools do. They widen participation, lower friction, and set off second-order innovation no one can count in advance. Britannica’s history of early printing makes the scale of that shift vivid.
The spreadsheet did not end accounting. And yes, the spreadsheeters suddenly had competition—from EVERYONE IN THE ENTIRE COMPANY. Good. Spreadsheets did not just replace pen-and-ink ledgers; they changed the pace and shape of thought. The original spreadsheet pitch was basically: ask “what if,” change any number, instantly recalculate all numbers, and explore more alternatives before you commit. That sounds almost quaint now, but it was a cognitive revolution. What had often been a slow, manual exercise that might take days or weeks turned into something much closer to interactive thinking, and the quality of decisions improved with it. The Computer History Museum’s archival VisiCalc material still captures that magic surprisingly well.
The word processor did not kill writing; it made revision the native state of prose. The digital camera did not end art; it gave painting permission to stop being a photocopier. Better tools do not make us less human. They make more human capability economically available.
Where we are making the real mistake with AI is much more mundane. We keep trying to use AI to rescue old tools when what we actually need are the new tools.
When machines are dumb, humans adapt
 Before we even get to computing, it is worth pausing at the typewriter.
Before we even get to computing, it is worth pausing at the typewriter.
QWERTY, whatever exact mix of causes produced it, is best understood as a keyboard layout shaped around machine-era constraints more than the flourishing of the human hand. Or, to put it a little more bluntly, the human interface was de-optimized to the maximum extent possible to accommodate for the limitations of the machine. Even the history of its origin is still debated, which is part of the point. The layout endured not because it was perfectly human-centered, but because it fit a world of mechanical compromises and path dependence. We are still living inside that compromise. Apologies to the Dvorak fans. Smithsonian has a good walk through the history.
That is the larger rule. When machines are dumb, we adapt to them. We take courses to learn how to use them. We memorize commands. We read manuals. We perform tiny rituals to make stubborn machinery behave. We had to RTFM to set the clock on a VCR.
But maybe, just maybe, those days are starting to end. Maybe the point of AI is that the machine starts doing the adapting. Maybe now, we are TFM.
When machines are dumb, humans adapt. The real promise of AI is that the machine starts doing the adapting instead.
From punch cards to natural language
 The history of computing is, among other things, the history of making machines adapt more to people and people adapt less to machines.
The history of computing is, among other things, the history of making machines adapt more to people and people adapt less to machines.
In the beginning, programming was brutally literal. Punch cards lasted longer than many people now remember; IBM’s Model 29 card punch remained in production until 1984. That was not so much “using a computer” as negotiating with an extremely powerful clerk. Musically, it was like reaching inside the piano and plucking strings rather than playing the keys. This short history of the IBM 029 is a useful reminder of just how physical and painstaking early computing could be.
The command line was already a huge step forward because the machine at least answered back. But it still demanded that the human being learn the machine’s syntax first. Then DOS showed up, and that was a much bigger step than people sometimes remember. It was still text, still command-driven, still unforgiving in its own way. But it gave you stable commands, remembered patterns, repeatable moves. To borrow the musical analogy again, command-line computing was like striking notes one by one; DOS was when you started getting chords.
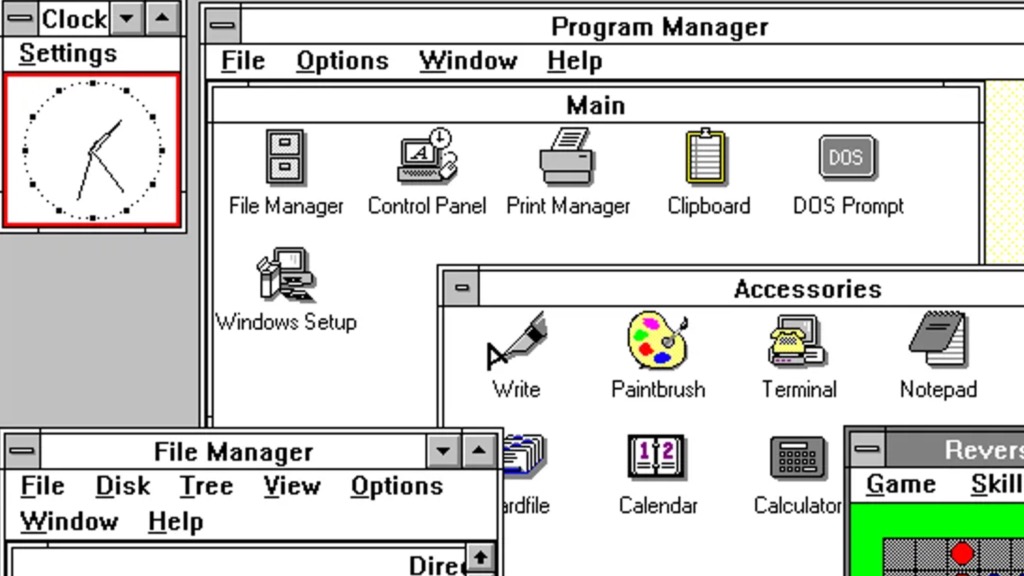 Windows then moved the story forward again. Windows 1.0 introduced a graphical environment on top of MS-DOS for IBM-compatible PCs. A few years later, Windows for Workgroups 3.10 became the first version of Windows with networking support built in. That was the killer move. Windows stopped being merely a friendlier surface and started becoming connected work infrastructure. Raymond Chen’s account of Windows for Workgroups is still the cleanest shorthand for why networking mattered so much.
Windows then moved the story forward again. Windows 1.0 introduced a graphical environment on top of MS-DOS for IBM-compatible PCs. A few years later, Windows for Workgroups 3.10 became the first version of Windows with networking support built in. That was the killer move. Windows stopped being merely a friendlier surface and started becoming connected work infrastructure. Raymond Chen’s account of Windows for Workgroups is still the cleanest shorthand for why networking mattered so much.
It also reminds us of something else that matters for this essay: none of this looked inevitable at the time. The operating-system field was crowded, messy, and full of plausible futures. The Voice OS era, if that is where this goes, will not begin with one obvious winner descending from the mountain.
Craig Mundie saw the turn years ago
Craig Mundie understood this transition long before the current AI boom made it obvious. In one 2009 talk, he said we were going to move “beyond this enhanced GUI to a real natural user interface,” and he described one key attribute of that future as “speaking to the machine and having it speak back to you,” with context doing far more of the work. In another talk that same year, he said the shift toward NUI would be critical if computers were to become “much more of a helper for people and less of just a tool.” You can hear the whole thesis already there in embryo in his Microsoft Research Faculty Summit remarks and his later “How tomorrow’s technologies will shape your world” speech.
That remains one of the deepest interface ideas anyone from the Windows era ever articulated. As our computers become more powerful, we should become more human in the way we use them. The burden should shift from us to the machine. The machine should infer more, remember more, listen better, and speak better. The software should begin to disappear into the interaction.
That is the real progression. Punch cards reached into the mechanism. The command line asked us to learn the machine’s language. DOS gave us stored commands and reusable structures. The GUI let us navigate visually. NUI asks the machine to do the translating.
And if that progression is real, voice is not some side feature bolted onto the future. Voice is one of the most important interface battlegrounds in the whole AI era.
Voice is not a feature. It is a frontier.
Voice is the natural endpoint
Talking is still the most natural interface most humans possess.
Voice is fast. Voice preserves flow. Voice carries hesitation, emphasis, ambiguity, tone, confidence, and urgency in a way most software interfaces never have. Voice works when your hands are busy, when your eyes are elsewhere, or when your thought is still arriving while you are speaking. Dave Killeen put the practical side of this beautifully when he said, “The keyboard is such a bottleneck,” and argued that moving more AI work into voice creates not just speed, but a deeper state of flow. That feels exactly right to me. (Dave’s post is worth a look.)
That is why I use voice with AI constantly now. Parts of the thinking behind this essay were dictated aloud. And dictated thinking has a very particular texture to it: it loops, wanders, doubles back, inserts side thoughts, half-forms an idea, abandons it, then rediscovers it from another angle.
It sounds more like this:
“Okay, wait, hang on, because I think there are actually two things here and I may be conflating them, which is maybe the point, but one is just voice as input, right, faster than typing, less friction, sure, fine, all good, but that is not actually the big thing, or not the whole thing, because if I’m just talking my prompt into the same box, then I’m basically using Google with lungs, which is better, but not that much better, whereas the thing I think we’re heading toward is I say, ‘What do we need to worry about today?’ and it says, ‘Three things, and by the way the second one is worse than you think,’ and then we actually work it through together and maybe one part goes to Perplexity, another part goes somewhere else, and hold on, if that’s true, then the model may not be the interface at all…”
That is not polished prose. It is thinking. And increasingly, that is what good AI interaction feels like: not query entry, but externalized thought.
OpenAI’s own training materials now carve this distinction cleanly. Voice in ChatGPT, they explain, includes both Dictation—where you speak and watch your words appear as text—and Voice Mode, the two-way version in which you speak directly to ChatGPT and hear it answer back. That is not just a product distinction. It is the conceptual gap that matters most for this whole essay: the difference between talking into software and actually being in conversation with it. (OpenAI Academy’s guide explains the distinction well.)
Voice is the doorway. Humanity is the design brief.
Even so, I still think “Voice OS” is the right term for now, because it gets at the big interface shift quickly and clearly.
There is, however, a deeper thought sitting underneath it. What matters is not just the voice. It is the humanity of the interface. A voice can be efficient and still feel dead. A voice can be accurate and still feel exhausting. A voice can answer correctly and still be unbearable to live with. What people may actually end up wanting is not merely a system they can speak to, but a system that feels recognizably human in the ways that matter: memory, timing, empathy, tone, humor, tact, challenge, encouragement, and taste.
That may be why, a few years from now, people end up calling this something more ambitious than Voice OS. Maybe it becomes Human OS. I would not force that label yet. But I do think the idea is already there, quietly percolating.
OpenAI’s own personality settings hint at the same thing. They define personality as the style and tone ChatGPT uses—a combination of traits, voice, and behavior that shapes how answers feel. That is a fascinating tell. It suggests that even the people building the models know the contest is no longer just about intelligence. It is also about relationship. (OpenAI’s personality documentation makes that explicit.)
We are not going to spend our days inside a voice that feels like airport signage. We are going to spend our days inside a presence. The winners will not simply sound good. They will feel workable.
Voice may be the doorway. Humanity is the design brief.
What a Voice OS would actually need to do
If voice becomes the front door to AI, then the winning layer will need to be much more than speech recognition with a nice personality.
It will need to be multi-model on purpose. The future is going to be multi-model for a long time, and probably forever. Different models will be better at different things. Some will reason better. Some will be faster. Some will be cheaper. Some will be safer. Some will be better at research, others at orchestration, others at action. Perplexity is already sketching part of that architecture: its Research mode automatically selects the optimal models for a task, while Model Council runs the same query across three models and synthesizes a unified answer. That is not a Voice OS yet. But it is a clue, and an important one. (Perplexity’s explanation of Research mode is a useful signal.)
It will need reach, not just eloquence. A Voice OS cannot just be good at talking. It has to connect language to calendars, CRM, knowledge bases, workflows, communications, analytics, and whatever other strange plumbing actually runs the enterprise. Otherwise it is just eloquent middleware.
It will need memory. A Voice OS without continuity is just amnesia with better diction. The winning layer has to remember the user, the company, the work, the patterns, the preferences, the unresolved threads, the emotional context, and the operating cadence. Not in some vague demo sense. In the lived sense.
It will need to move from answers to action. Resolving an intent is not enough. Answering a question is not enough. Even sounding convincingly human is not enough. The real job is to connect language to enterprise systems, workflows, permissions, memory, policy, analytics, and outcomes.
The real job is not to have a nicer conversation. The real job is to get real work done through conversation.
It will need to understand conversation the way humans actually live it. This is where most people still underestimate the problem. Human beings do not speak in neat product-manager paragraphs. We loop. We mumble. We interrupt ourselves. We revise on the fly. We say, “No, wait, that’s not quite it.” We trail off and come back. A real Voice OS has to handle interruption, hesitation, clarification, uncertainty, repair, drift, and change of mind without making the user feel broken. That is why the technical work here is deeper than it first appears. Gartner’s own category description keeps coming back to the same hard problems: multiple channels, mixed modalities, integrations, and enterprise-grade tooling for real conversational systems. (Gartner’s CAIP definition lays out that broader scope.)
It will need governance built into the experience. If this layer is going to sit between humans and enterprise systems, it has to be governable. That means permissions, auditability, explainability, security, policy, monitoring, escalation, compliance, and operational trust. The future helper cannot just be charming. It has to be accountable.
And yes, it will need personality. Not mascot design. Not branding fluff. Not a cute wrapper around a prompt. Personality is a product surface. It is how the system feels to live with. Whether it can be warm without being cloying, funny without becoming annoying, serious without sounding bureaucratic, concise without feeling cold, and confident without becoming smug. We are not going to spend our days inside a system that sounds like a laminated instruction manual. Personality is part of the operating system.
It will also need humor. This sounds soft until you think about it for five minutes. Windows did not win because the windows were prettier. It won because, once networking arrived, it became more connected to the actual work of the office. My hunch is that the killer punch for a Voice OS may be something similarly sticky but under-discussed: humor. Not comedy as entertainment. Lightness as interface design. The system you live inside all day cannot merely be accurate. It has to be emotionally workable.
Where could a Voice OS come from?
The obvious candidates are the model companies and the incumbent platform giants, and it would be strange not to take them seriously. OpenAI already supports real-time voice conversations. Perplexity is already teaching users to think above the level of any single model. Amazon has rebooted Alexa as Alexa+, describing it as more conversational, smarter, more personalized, and more able to get things done. Apple has been promising a more personalized Siri with deeper awareness of personal context and cross-app action, but those features were delayed into 2026. Microsoft, meanwhile, retired Cortana as a standalone Windows app back in 2023. (Amazon’s Alexa+ announcement, Reuters on Siri’s delay, and Microsoft’s Cortana notice tell the story.)
But that is exactly why I do not think the answer is most likely to come from those camps.
The model companies are obvious contenders, but the case against them is not that they are weak. It is that the world is increasingly multi-model. If the best experience in 2026 or 2027 depends on routing across different reasoning engines, different cost curves, different speed profiles, and different safety properties, then the stable layer in the experience may not be the model. It may be the thing that knows which model to use, when to use it, and how to make the whole system feel coherent. In that world, the model becomes essential but not sufficient. The operating layer sits one level above it.
The incumbent voice assistants have the opposite problem. They had the channel first. They had the device adjacency. They had the wake words, the installed base, and the public imagination. And yet, after more than a decade, none of them has become the general-purpose, work-centric, voice-first operating environment imagined in that 7:12 a.m. scene. Microsoft squandered Cortana. Apple has moved cautiously. Amazon may yet do something interesting with Alexa+, but even there the burden of proof is not trivial. When players have had a ten-year head start and still have not seized the control point, one has to at least entertain the possibility that the winner comes from somewhere else.
Which is why I keep coming back to one of the less glamorous corners of enterprise software.
The category hiding in plain sight
 Gartner’s public definition of Conversational AI Platforms is already broader than the old chatbot frame. It describes CAIPs as SaaS products that enable applications simulating human conversation across multiple channels and media, using a mix of modalities such as text, voice, and visual content, with coding options ranging from pro-code to no-code. These platforms are used to create, deploy, and manage AI-driven conversational interfaces for both customer-facing and internal interactions. That is already a much bigger description than “customer-service bot builder.” (Gartner’s public category definition is unusually helpful here.)
Gartner’s public definition of Conversational AI Platforms is already broader than the old chatbot frame. It describes CAIPs as SaaS products that enable applications simulating human conversation across multiple channels and media, using a mix of modalities such as text, voice, and visual content, with coding options ranging from pro-code to no-code. These platforms are used to create, deploy, and manage AI-driven conversational interfaces for both customer-facing and internal interactions. That is already a much bigger description than “customer-service bot builder.” (Gartner’s public category definition is unusually helpful here.)
The forecasts are bigger still. Gartner said in late 2024 that 85% of customer-service leaders would explore or pilot customer-facing conversational GenAI in 2025. It has also said that by 2028 at least 70% of customers will use a conversational AI interface to start their customer-service journey, that 70% of customer-service journeys will begin and be resolved in conversational third-party assistants built into mobile devices, that 30% of Fortune 500 companies will offer service through only a single AI-enabled channel that handles text, image, and sound, and that by 2029 agentic AI will autonomously resolve 80% of common customer-service issues.
At some point, if you read those predictions carefully enough, it stops sounding like a category about deflecting calls and starts sounding like a category about owning the front door to enterprise AI (Gartner’s 2024 press release is the cleanest public summary).
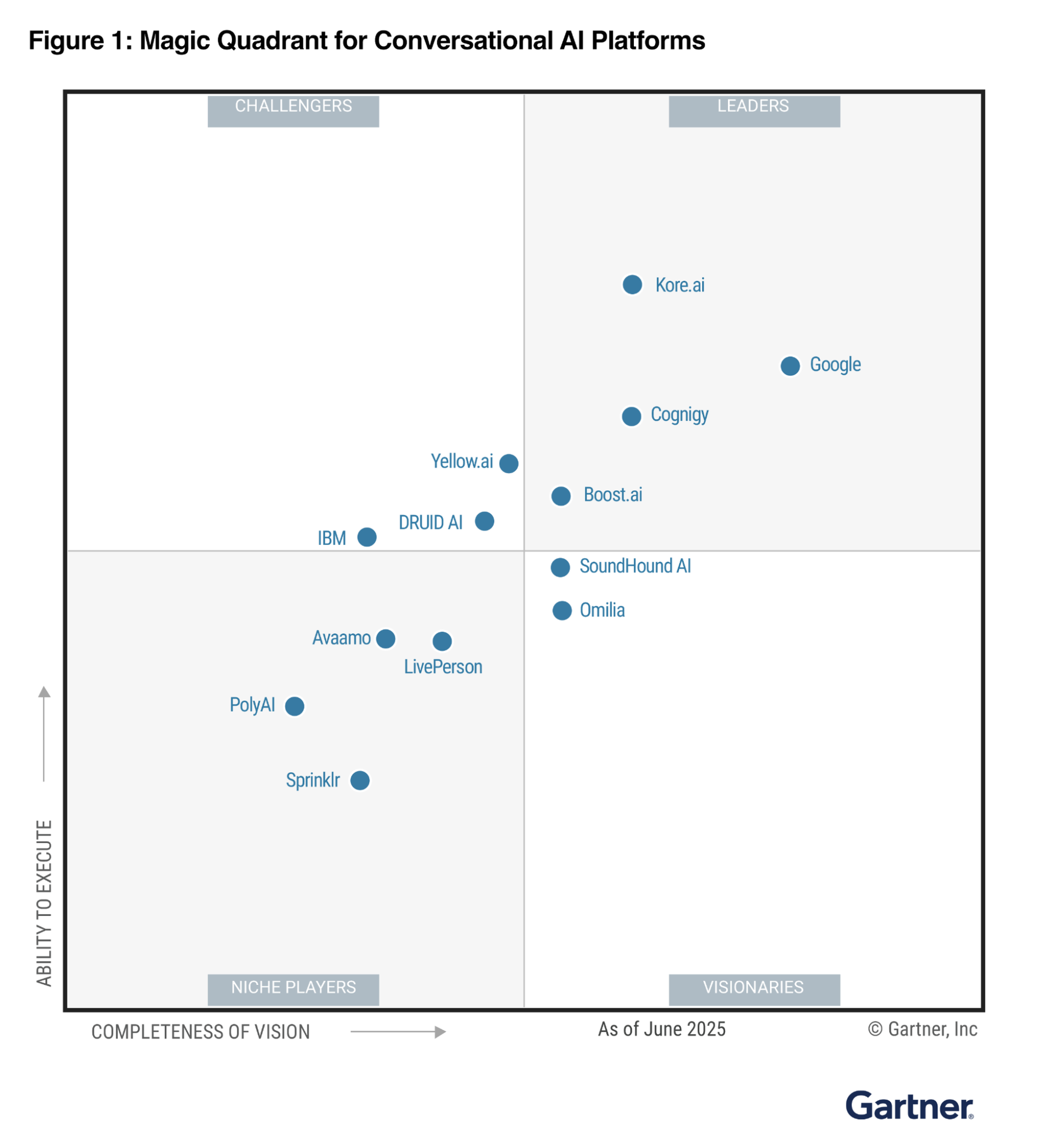 Gartner® Magic Quadrant™ for Conversational AI Platforms, June 2025. Reproduced from the public companion materials hosted by Google Cloud. Report access is also available via Kore.ai and LivePerson.
Gartner® Magic Quadrant™ for Conversational AI Platforms, June 2025. Reproduced from the public companion materials hosted by Google Cloud. Report access is also available via Kore.ai and LivePerson.
Public summaries of the 2025 Magic Quadrant put thirteen vendors in the field: Google, Kore.ai, Cognigy, boost.ai, Yellow.ai, DRUID AI, IBM, SoundHound AI, Omilia, LivePerson, Avaamo, Sprinklr, and PolyAI. One disclosure here: I worked at Sprinklr and have been a customer for years, so I am not exactly a neutral observer of this neighborhood. If you want my more developed view on Sprinklr’s AI-era opportunity, I wrote about it separately in Reputation OS. Even with that caveat, though, I think the larger point holds. This is not just a market for customer-service tooling. It may be one of the places where the next operating-system layer is quietly learning to walk. (CX Today’s public rundown is useful for the vendor list.)
The category is called Conversational AI Platforms. The more interesting possibility is that it is quietly incubating a Voice OS.
PolyAI is particularly interesting in that frame its product instinct appears aimed at the right problem. Unlike many vendors that came up through chat and then extended outward, PolyAI’s public thesis has been voice first. When it introduced Agent Studio, it described the platform as voice-first and omnichannel and explicitly argued that solving voice first is the best way to build a robust “brain” for enterprise customer service that can then be reused across other channels. This is the kind of instinct a Voice OS would need: Start with the hardest, most human modality, get that right, and then radiate outward. That does not mean PolyAI wins. It does mean the company may be solving the right problem in the wrong analyst frame.
The fact that Gartner’s current public framing still places PolyAI as a Niche Player may actually make the story more interesting, not less. If voice really is the hardest channel to automate well, a company that starts there may look smaller in the present tense while being better aligned with the future. (PolyAI’s Agent Studio launch post is worth reading with that lens.)
To the thirteen companies in Gartner’s quadrant: Here is your PRD
This is not a roadmap for winning a few more customer-service bake-offs. This is a roadmap for breaking out of the conversational-AI box and becoming something much larger: The operating layer through which people actually use AI.
I: Start in the contact center, but do not stay there.
Customer service is the beachhead, not the destiny. It is where the pain is obvious, the ROI is countable, and the budget already exists. Fine. Start there. But if that remains the boundary of your ambition, you will get trapped inside a category that is too small for the thing you are actually building. You are not merely automating inquiries. You are learning how to mediate work through language.
II: Become ruthlessly model-agnostic.
If your unspoken assumption is that your moat will be access to one model, one provider, or one privileged stack, you are building on sand. The winning layer will not be ideological. It will be practical. It will know what to call, when to call it, when to blend outputs, when to privilege speed over depth, and when to hide all of that from the user so the experience feels coherent rather than cobbled together. The existence of products like Perplexity’s Research mode and Model Council should be a giant blinking warning sign: users are already being trained to think above the level of any single model.
III: Move from conversation design to action orchestration.
This is the big one. Resolving an intent is not enough. Answering a question is not enough. Even sounding impressively human is not enough. The companies that matter in the next phase will be the ones that connect language to systems, systems to workflows, and workflows to outcomes. They will stop thinking of themselves as conversation designers and start thinking of themselves as orchestrators of action.
IV: Treat memory as core product, not decorative feature.
A surprising amount of so-called personalization in software is still just polite amnesia. A Voice OS cannot work that way. It has to remember what matters. It has to know the user’s style, priorities, projects, history, rhythms, and unresolved threads. It has to carry continuity across time, tasks, and channels, because without that, every interaction is a reboot.
V: Make humanity an engineering problem.
The future interface will not win because it has a voice. It will win because it has humanity. That means turn-taking, interruption handling, clarification, timing, empathy, tact, challenge, encouragement, and the ability to notice when the user is uncertain, frustrated, tired, rambling, or simply wrong. This is not brand polish. It is systems design.
VI: Build multimodal systems with voice as the front door.
Voice-first does not mean voice-only. The winning systems will talk when talking is best, show when showing is better, and move gracefully across text, image, screen, sound, and action without making the user feel they are bouncing between unrelated tools. Voice may be the front door. It does not have to be the whole house.
VII: Treat governance as part of the experience.
Governance is not the dreary back-office appendix to delight. It is part of delight. If a system cannot be trusted with permissions, policies, escalations, explanations, security, compliance, and auditability, it will never become the layer through which serious work is done. The future helper has to be accountable enough that enterprises will let it sit close to the nerve endings of the business.
VIII: Treat personality as product.
This is where the category could still lose the plot. Personality is not decorative. It is not some cute optional wrapper. It is part of the core experience. How the system feels to live with will matter almost as much as what the system can do. We are not going to spend our days inside a system that sounds like a laminated instruction manual. We are going to spend our days inside a relationship of some kind, however strange and asymmetrical that relationship may be.
IX: Make room for humor.
This sounds soft until you think about it for five minutes. The killer punch for a Voice OS may be something sticky but under-discussed: humor. Not comedy as entertainment. Lightness as interface design. The system you live inside all day cannot merely be accurate. It has to be emotionally workable. A system that is competent but joyless will feel like an IVR with delusions of grandeur.
X: Build a habitat, not a feature.
Operating systems win because other people build on top of them. They become the place where work happens. If you want to become the Windows of AI, you cannot remain merely an application layer. You need extensibility, orchestration hooks, partner ecosystems, workflow surfaces, developer affordances, and the ability for other people to treat your layer as the place where intelligence gets invoked. That is the point at which a category stops being software and starts becoming habitat.
The Copernican shift

What makes this so interesting is that the market may not yet understand what it is actually buying.
“Conversational AI Platforms” feels like one of those temporary category labels that appears in the middle of a technological transition, when the old description is still technically accurate but no longer strategically adequate. It is a perfectly useful name if all you want is a better answer to customer questions. It is a comically inadequate one if what you are actually buying is the first rough draft of a new operating-system layer.
That, to me, is the Copernican shift here. We think these vendors are in the automation business because automation is the easiest ROI story to tell. Service leaders can count calls deflected, handle times reduced, agent hours saved, and budget recaptured. Fine. That is where the money is today. But categories often enter the world through the least imaginative version of themselves. The spreadsheet first looked like a faster ledger. The browser first looked like a more elegant way to retrieve documents. The smartphone first looked like a phone that happened to do email. Early use cases are real, but they are often radically incomplete.
So it may be here. These companies may have entered the enterprise through customer service because that is where the pain was obvious. But the capabilities they are developing do not belong only to customer service. They are learning how to make machines listen. They are learning how to make them speak. They are learning how to handle interruption, ambiguity, escalation, memory, emotion, and context. They are learning how to connect language to systems, systems to workflows, and workflows to outcomes. That is not just service automation. Those are the primitive functions of a new computing layer.
The question beneath the question
And that is why the moat question has to be asked differently. The thin version of the question is what happens to these companies as the models get better. The more interesting version is what happens if the scarce thing in a multi-model world is no longer raw intelligence, but mediation. What if the real control point is the layer that knows which model to call for which task, that holds context while the models beneath it change, that connects language to calendars and workflows and policies and repositories, that governs action, preserves trust, remembers what matters, and makes the whole experience feel coherent rather than cobbled together?
If that is right, then the most valuable company in the stack may not be the one with the single best model. It may be the one that makes many models usable.
That is a much bigger business than people currently think. And it is why this odd little Gartner category matters. Buried inside a quadrant that sounds like a niche corner of contact-center software is a set of companies learning exactly the behaviors a Voice OS would need. Most of them will not make that leap. Some will remain excellent at what they already do. Some will be flattened into features. Some will be absorbed into larger stacks. That is how every platform transition works. But every so often, hidden inside one of those apparently narrow markets, there is a company learning the future in plain sight.
That is what makes this field so interesting to me. Not because it helps enterprises answer customer questions more cheaply, though it does, but because somewhere inside it may be a company learning how to become the stable environment humans live inside while the underlying models, tools, channels, and systems keep changing around them.
The Windows of the AI age, in other words, will probably not be a window. It will be a voice, and a personality—someone funny, someone we like, maybe even, in some strange new way, a friend. The question is not whether that layer gets built. It is which company, from this messy and underestimated field, has the imagination to build it first.